Apache Storm
Apache Storm은 분산형 실시간 처리 프레임워크로써, 노드마다 초당 수백만 개의 레코드를 처리하고 한 번에 하나씩 이벤트를 처리하는 기능이 있다. 그리고 1초의 지연마저도 큰 손실이 되는 매우 민감한 어플리케이션을 다루는데 사용되고, 추천엔진 제작, 의심스런 활동 트리거 등에 사용하고 있다. 또한 상태 저장 없이(stateless), 중요한 메타데이터 정보를 유지하기 위한 조정(coordinating)을 목적으로 주키퍼를 사용한다.
클러스터 구조
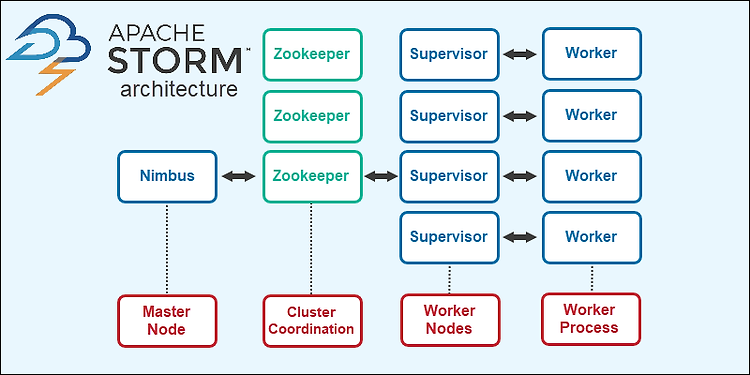
스톰은 마스터-슬레이브(master-slave)구조로 되어있고 님버스(nimbus)가 마스터이고, 수퍼파이저(supoervisor)가 슬레이브가 된다.
- 님버스(nimbus) : 스톰 클러스터 마스터노드로 클러스터 안에서 나머지 모든 노드를 작업자 노드라고 한다. 님버스는 작업자 노드에게 데이터를 분배하고, 작업을 할당한다. 또한 작업자의 장애를 모니터하고, 장애가 발생하면 다른 작업자에게 작업을 다시 할당한다.
- 수퍼바이저(Supervisor) : 수퍼바이저는 님버스가 할당한 작업을 완료하는 역할을 하고, 가용한 자원 정보를 전송한다. 개별 작업자 노드는 정확히 한 개의 수퍼바이저가 있으며, 한 개 이상의 작업자 프로세스를 갖고 있고, 각 수퍼바이저는 다중 작업자 프로세스를 관리한다.
[Strom 구조]
스톰은 상태정보를 저장하지 않으며 님버스와 수퍼바이저가 상태정보를 주키퍼에 저장한다. 님버스가 스톰 어플리케이션의 실행 요청을 받으면 주키퍼로부터 가용한 자원을 요구하고 나서, 사용할 수 있는 수퍼바이저에게 작업 스케줄을 준다. 또한 주키퍼에 진행 상황에 대한 메타데이터를 저장하고, 장애가 발생하여 님버스가 재시작되면 어디서 부터 재시작할 수 있는지 알 수 있다.
Strom의 개념
- 스파우트(SPout) : 외부소스 시스템에서 데이터 스트림(Tuple)을 읽고 나중에 처리하기 위해 토폴로지(Topology)에 전달하는데 사용된다. 스파우트는 신뢰할 수 있거나 아닐 수도 있다.
- 신뢰할 수 있는 스파우트 : 실행 중에 장애가 발생할 경우 데이터의 재연이 가능. 이런 경우 스파우트는 이후 과정의 처리를 위해 내보내는 이벤트마다 ACK를 기다린다. 더 많은 시간이 소요되지만, 단 한 개의 레코드 손실 없이 관리를 원하는 프로그램들에게는 도움이 된다.
- 신뢰할 수 없는 스파우트 : 이벤트의 장애 발생 시 다시 이벤트를 내보내는 데에 신경쓰지 않는다. 100~200개의 레코드가 손실되는 것이 별 다른 의미가 없는 경우에 유용하게 사용할 수 있다.
- 볼트(Bolt) : 토폴로지의 모든 처리 작업이나, 레코드 처리를 Bolt에서 수행하는 것이며, 스파우트가 보낸 스트림 스톰 볼트가 수신하고, 처리가 끝나면 해당 레코드는 볼트를 통해 데이터베이스, 파일 또는 저장소 시스템에 저장될 수 있다.
- 토폴로지(Topology) : 애플리케이션의 전체적인 흐름으로 프로그램 내에 스톰 토폴로지를 생성하고 스톰 클러스터에 등록한다. Batch job과는 달리 지속적인 동작을 한다. 토폴로지에 정의된 각 객체는 하나의 처리 로직을 포함하며 데이터를 읽어올 스트림을 정의할 수 있고 읽어들인 스트림을 처리할 처리 로직을 포함할 수 있다(Hadoop의 MR(Mapreduce)작업에 대응하는 컴포넌트)
- 스트림(Stream) : Storm에서는 일련의 튜플(Tuple)의 흐름을 스트림으로 정의하고 있는데, 이 스트림을 분산 환경에서 신뢰성있게 다른 스트림으로 전환 할 수 있는 기능을 제공한다. 튜플은 기본 데이터 타입(Premitive Data)이나 바이트 배열(Byte Array)을 포함할 수 있고 사용자 타입을 정의할 수도 있다.
[스톰 토폴로지 개념도]
- 한 개의 스파우트가 한 번에 여러 볼트에게 데이터를 보낼 수 있고, 모든 볼트에 대한 ACK를 주적할 수 있다.

참조
https://phoenixnap.com/kb/apache-storm
http://courspick.blogspot.com/2015/06/apache-storm-storm.html
Apache Storm
Apache Storm은 분산형 실시간 처리 프레임워크로써, 노드마다 초당 수백만 개의 레코드를 처리하고 한 번에 하나씩 이벤트를 처리하는 기능이 있다. 그리고 1초의 지연마저도 큰 손실이 되는 매우 민감한 어플리케이션을 다루는데 사용되고, 추천엔진 제작, 의심스런 활동 트리거 등에 사용하고 있다. 또한 상태 저장 없이(stateless), 중요한 메타데이터 정보를 유지하기 위한 조정(coordinating)을 목적으로 주키퍼를 사용한다.
클러스터 구조
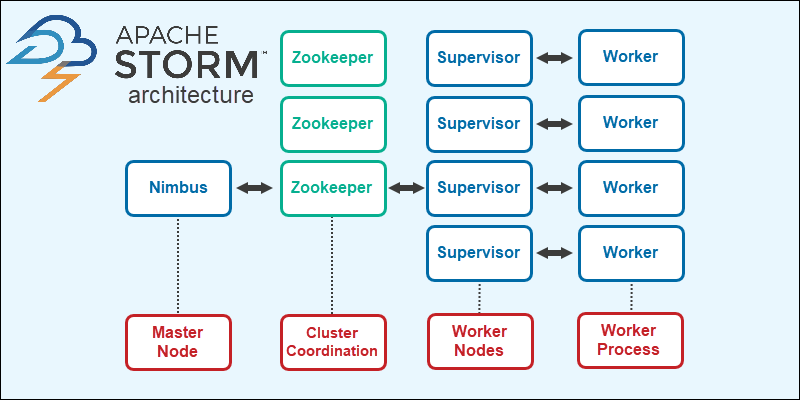
스톰은 마스터-슬레이브(master-slave)구조로 되어있고 님버스(nimbus)가 마스터이고, 수퍼파이저(supoervisor)가 슬레이브가 된다.
- 님버스(nimbus) : 스톰 클러스터 마스터노드로 클러스터 안에서 나머지 모든 노드를 작업자 노드라고 한다. 님버스는 작업자 노드에게 데이터를 분배하고, 작업을 할당한다. 또한 작업자의 장애를 모니터하고, 장애가 발생하면 다른 작업자에게 작업을 다시 할당한다.
- 수퍼바이저(Supervisor) : 수퍼바이저는 님버스가 할당한 작업을 완료하는 역할을 하고, 가용한 자원 정보를 전송한다. 개별 작업자 노드는 정확히 한 개의 수퍼바이저가 있으며, 한 개 이상의 작업자 프로세스를 갖고 있고, 각 수퍼바이저는 다중 작업자 프로세스를 관리한다.
[Strom 구조]
스톰은 상태정보를 저장하지 않으며 님버스와 수퍼바이저가 상태정보를 주키퍼에 저장한다. 님버스가 스톰 어플리케이션의 실행 요청을 받으면 주키퍼로부터 가용한 자원을 요구하고 나서, 사용할 수 있는 수퍼바이저에게 작업 스케줄을 준다. 또한 주키퍼에 진행 상황에 대한 메타데이터를 저장하고, 장애가 발생하여 님버스가 재시작되면 어디서 부터 재시작할 수 있는지 알 수 있다.
Strom의 개념
- 스파우트(SPout) : 외부소스 시스템에서 데이터 스트림(Tuple)을 읽고 나중에 처리하기 위해 토폴로지(Topology)에 전달하는데 사용된다. 스파우트는 신뢰할 수 있거나 아닐 수도 있다.
- 신뢰할 수 있는 스파우트 : 실행 중에 장애가 발생할 경우 데이터의 재연이 가능. 이런 경우 스파우트는 이후 과정의 처리를 위해 내보내는 이벤트마다 ACK를 기다린다. 더 많은 시간이 소요되지만, 단 한 개의 레코드 손실 없이 관리를 원하는 프로그램들에게는 도움이 된다.
- 신뢰할 수 없는 스파우트 : 이벤트의 장애 발생 시 다시 이벤트를 내보내는 데에 신경쓰지 않는다. 100~200개의 레코드가 손실되는 것이 별 다른 의미가 없는 경우에 유용하게 사용할 수 있다.
- 볼트(Bolt) : 토폴로지의 모든 처리 작업이나, 레코드 처리를 Bolt에서 수행하는 것이며, 스파우트가 보낸 스트림 스톰 볼트가 수신하고, 처리가 끝나면 해당 레코드는 볼트를 통해 데이터베이스, 파일 또는 저장소 시스템에 저장될 수 있다.
- 토폴로지(Topology) : 애플리케이션의 전체적인 흐름으로 프로그램 내에 스톰 토폴로지를 생성하고 스톰 클러스터에 등록한다. Batch job과는 달리 지속적인 동작을 한다. 토폴로지에 정의된 각 객체는 하나의 처리 로직을 포함하며 데이터를 읽어올 스트림을 정의할 수 있고 읽어들인 스트림을 처리할 처리 로직을 포함할 수 있다(Hadoop의 MR(Mapreduce)작업에 대응하는 컴포넌트)
- 스트림(Stream) : Storm에서는 일련의 튜플(Tuple)의 흐름을 스트림으로 정의하고 있는데, 이 스트림을 분산 환경에서 신뢰성있게 다른 스트림으로 전환 할 수 있는 기능을 제공한다. 튜플은 기본 데이터 타입(Premitive Data)이나 바이트 배열(Byte Array)을 포함할 수 있고 사용자 타입을 정의할 수도 있다.
[스톰 토폴로지 개념도]
- 한 개의 스파우트가 한 번에 여러 볼트에게 데이터를 보낼 수 있고, 모든 볼트에 대한 ACK를 주적할 수 있다.
참조
https://phoenixnap.com/kb/apache-storm
http://courspick.blogspot.com/2015/06/apache-storm-storm.html