Kafka Producer & Consumer API
- producer API는 응용 프로그램에서 Kafka 클러스터로 데이터 스트림을 보낼 수 있다.
- Consumer API는 응용프로그램에서 Kafka 클러스터에서 topics에 대하여 데이터 스트림으로 받을 수 있다.
kafka consumer, producer 를 자바로 구현하려면 kafka-clients 라이브러리가 필요하다.
## maven
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.1</version>
</dependency>
## gradle
compile group: 'org.apache.kafka', name: 'kafka-clients', version: '2.2.1'
- kafka client는 kafka cluster에 있는 레코드들을 기록한다.
- Producer는 스레드로부터 safe하고, 스레드들을 통해 단일 producer 인스턴스를 공유하는 것이 다중 인스턴스를 갖는거보다 빠르다.
Producer의 초기설정 파라미터
- bootstrap.server : Kafka Broker 주소의 목록으로 hostname:prot 형식으로 지정한다. 한 개 또는 여러개의 브로커를 지정할 수 있다.
- key.serializer : 메시지는 key 쌍으로 이루어진 형태로 Kafka Broker에게 전송된다. Broker는 이 키 값이 바이트 배열로 돼있다고 가정하고 프로세서에게 어떠한 직렬화 클래스가 키 값을 바이트 배열로 변환할 때 사용됐는지 알려줘야한다. 이 속성이 Producer에게 어떤 클래스가 메시지 키를 직렬화 하면서 사용됐는지 나타난다(내장 직렬화 클래스 : ByteArraySerializer, StringSerializer, IntegerSerializer)
- value.serializer : Producer가 값을 직렬화 하기 위해 사용할 클래스를 알려준다. 직접 제작한 직렬화 클래스를 사용할 수도 있다.
- acks : 메시지가 성공적으로 commit 되기 전에 producer가 reader로부터 ACK를 받는 경우사용된다.
- ack=0 : 프로듀서는 서버로부터의 ACK를 기다리지 않는다. 프로듀서는 어느 시점에 메시지가 손실됐는지 모르고, 메시지는 reader broker에 의해서 commit되지 않는다. 이 경우 재시도는 발생하지 않으며, 메시지는 완전히 손실될 수 있다. 이 설정은 매우 높은 처리 성능이 필요하고, 잠재적인 메시지 손실 가능성이 문제되지 않을 경우 사용
- ack=1 : Producer는 reader가 지역 로그에 메시지를 기록하자마자 ACK를 수신한다. Reader가 로그에 메시지 기록을 실패하면 Producer는 retry-policy set에 맞게 데이터를 재전송을 하고, 잠재적 메시지 손실 가능성을 없앤다. 만약 reader가 Producer에 ACK를 반환한 다음, 다른 Broker에게 메시지를 복제하기 전에 다운되면 손실이 발생할 수 있다.
- ack=all : Reader가 모든 복제에 대해 ACK를 수신한 경우에만 Producer는 ACK를 받는다. 장애에 대처할 수 있을 정도로 복제수가 충분하다면 데이터는 손실하지 않는 안전한 설정으로 처리성능이 낮다는 점이 있다.(kafka문서에서는 all을 추천)
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("block.on.buffer.full", "true");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");ProducerRecord 객체
- Producer는 ProducerRecord라는 객체를 제공하는데 Topic 이름, 파티션 번호, timestamp, key, value 등을 포함한다. key 등은 선택 파라미터지만 데이터를 보낼 topic과 value는 반드시 포함해야한다.
- 파티션 번호가 지정되면, 지정된 파티션은 레코드를 전송할 때 사용
- 파티션이 지정되지 않고 키가 지정된 경우 파티션은 키의 해시를 사용
- 키, 파티션 모두 지정하지 않은 경우 파티션은 라운드로빈 방식으로 할당.
ProducerRecord<String, String> recording = new ProducerRecord<String, String>("hello-kafka", "uMsg", msg); producer.send(recording);
Producer 코드
package com.study.kafka;
import java.util.Properties;
import java.util.Scanner;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class Producer {
public static void main(String[] args) throws Exception {
kafkaProducer();
}
private static void kafkaProducer() throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("block.on.buffer.full", "true");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
Scanner scan = new Scanner(System.in);
while (true) {
System.out.print("In > ");
String msg = scan.nextLine();
if (msg.equals("END"))
break;
ProducerRecord<String, String> recording = new ProducerRecord<String, String>("hello-kafka", "uMsg", msg);
try {
producer.send(recording);
} catch (Exception e) {
} finally {
producer.flush();
}
}
producer.close();
}
}Consumer
1. Kafka Consumer의 역할
- Topic 구독하기 : Consumer는 Topic을 구독하면서 시작된다. Consumer Group은 해당 Topic의 파티션 하부 세트가 할당된다. Consumer Process는 할당된 파티션에서 데이터를 읽는다.
- Consumer offset 위치 : Kafka는 메시지 offset을 유지하지 않는다. 그러므로 모든 Consumer는 자신의 consumer offset을 유지해야하고 Consumer API를 사용해 유지한다.
- 재연/되감기/메시지 Skip : Kafka Consumer는 Topic Partition에서 메시지를 읽는 시작점의 offset에 대해 전체적인 제어권을 갖고, Consumer API를 통해 시작 offset을 전달할 수 있다.
- Heartbeat : 지정된 파티션의 멤버쉽과 소유권을 확인하기 위해 Kafka Broker로 Heartbeat 신호를 주기적으로 내보내고, 정해진 시간 간격으로 Broker Reader가 Heartbeat를 수신하지 못하면, 파티션 소유권은 Consumer Group안의 다른 Consumer에게 다시 할당된다.
- offset commit : kafka는 consumer에서 읽는 메시지 위치나 offset을 관리하지 않는다. Consummer는 offset과 commit을 관리한다.
- Deserialization(역직렬화) : Producer는 Kafka에게 메시지를 보내기 전에 바이트 배열로 객체를 직렬화 한다. 마찬가지로 Kafka Consumer는 자바 객체를 바이트 배열로 역직렬화 한다.
2. Consumer 초기설정 파라미터
- bootstrap.server : kafka broker의 host:port 를 입력
- key.desrializer : 메시지 키를 직렬화 할수 있는 클래스를 지정하는 것으로 바이트 배열을 특정 키 형태로 역직렬화 한다.
- value.desrializer : ㅁ메시지를 역직렬화 하기 위해 사용
- group.id : 애플리케이션 생성시 Consumer Group을 정의하는 것은 필요에 따라 Consumer를 관리하고 성능을 향상시키는데 도움을 준다.(필수는은 아니지만 사용을 권장)
- enable.auto.commit : 설정된 주기에 따라 최근에 읽은 메시지의 오프셋을 자동으로 커밋(default : true)
- auto.commit.interval.ms : 매초마다 offster을 커밋하는 설정
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.setProperty("group.id", "test"); props.setProperty("enable.auto.commit", "true"); props.setProperty("auto.commit.interval.ms", "1000"); props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer 객체
KafkaConsumer 객체에 설정값을 넣으면 연결할 broker IP, Consumer Group명, 직렬화 클래스, commit을 하면서 사용할 offset 운영방안 등정보를 알려준다.
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);구독과 폴링
Consumer는 데이터를 받기위해 Topic을 구독한다. KafkaConsumer 객체는 subscribe() 함수를 가지고 있는데, Consumer가 구독하기를 원하는 Topic의 목록을 가져온다.
- public void subscribe(Collection topics) : Consumer가 등록을 원하는 Topic name 목록을 전달하는 것으로 메시지 데이터 처리에 영향을 줄 수 있는 default rebalancer(기본 리벨런서)를 사용
- public void subscribe(Pattern pattern, ConsumerRebalanceListener listener) : kafka에 존재하는 적합한 Topic을 대응시키는 Regex(정규식)을 전달하고 동적으로 처리한다. 정규식에 대응하는 새로운 토픽의 추가나 삭제시 리밸런서를 트리거한다. CoonsumerRebalanceListener는 해당 인터페이스를 구현하는 자신의 클래스를 가져오는 역할을 한다.
- public void subscribe(Collection topics, ConsumerRebalanceListener listener) : 토픽의 목록을 전달하고, ConsumerRebalanceListener를 수반한다.
consumer.subscribe(Arrays.asList("hello-kafka"));폴링은 kafka topic에서 데이터를 가져오는 것으로 consumer가 아직 읽지 않은 메시지를 반환한다.
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}Consumer 코드
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class Consumer {
public static void main(String[] args) throws Exception {
kafkaConsumer();
}
private static void kafkaConsumer() throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("hello-kafka"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
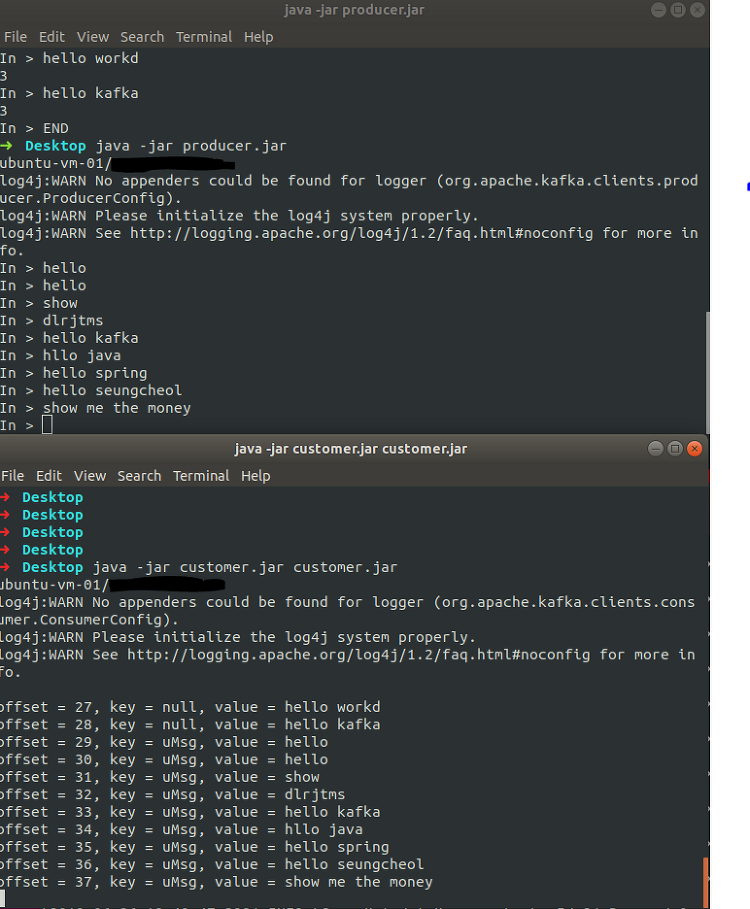
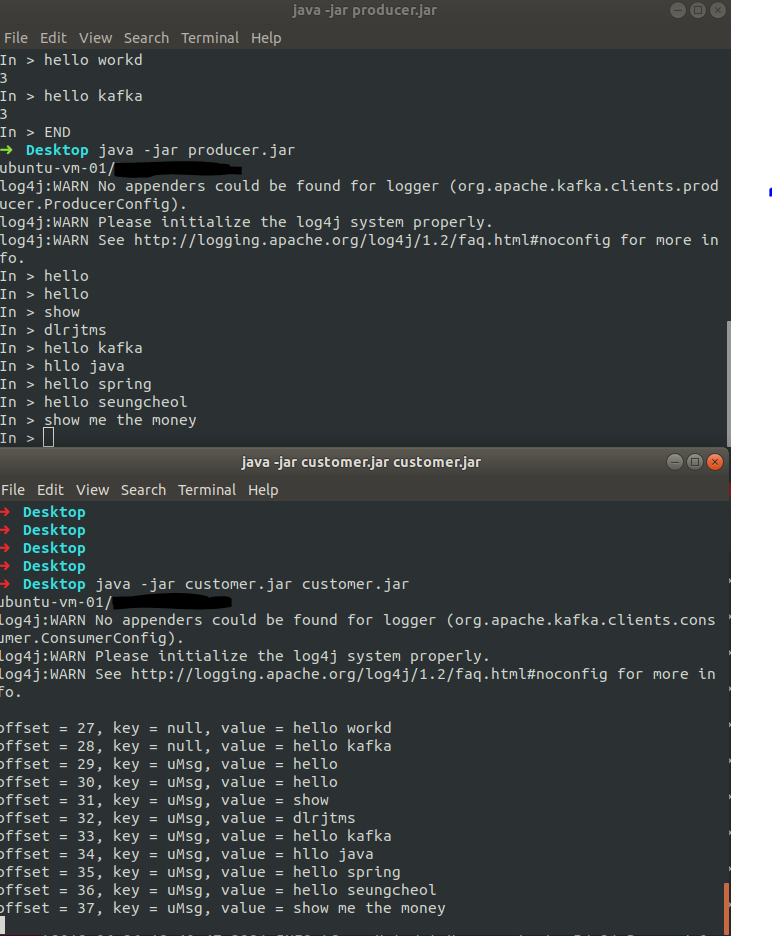
}결과
'Back-End > Kafka' 카테고리의 다른 글
| [Kafka] 5. kafka topic message 처리하기 (0) | 2023.04.25 |
|---|---|
| [Kakfka] 4. Kafka clusters (0) | 2023.04.24 |
| [Kakfa] 2, Kafka QuickStart (0) | 2023.04.24 |
| [Kafka] 1. Apache Kafka 개념 및 소개 (0) | 2023.04.24 |
| [Kafka] 0. Apache Zookeeper (0) | 2023.04.24 |
Kafka Producer & Consumer API
- producer API는 응용 프로그램에서 Kafka 클러스터로 데이터 스트림을 보낼 수 있다.
- Consumer API는 응용프로그램에서 Kafka 클러스터에서 topics에 대하여 데이터 스트림으로 받을 수 있다.
kafka consumer, producer 를 자바로 구현하려면 kafka-clients 라이브러리가 필요하다.
## maven
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.1</version>
</dependency>
## gradle
compile group: 'org.apache.kafka', name: 'kafka-clients', version: '2.2.1'
- kafka client는 kafka cluster에 있는 레코드들을 기록한다.
- Producer는 스레드로부터 safe하고, 스레드들을 통해 단일 producer 인스턴스를 공유하는 것이 다중 인스턴스를 갖는거보다 빠르다.
Producer의 초기설정 파라미터
- bootstrap.server : Kafka Broker 주소의 목록으로 hostname:prot 형식으로 지정한다. 한 개 또는 여러개의 브로커를 지정할 수 있다.
- key.serializer : 메시지는 key 쌍으로 이루어진 형태로 Kafka Broker에게 전송된다. Broker는 이 키 값이 바이트 배열로 돼있다고 가정하고 프로세서에게 어떠한 직렬화 클래스가 키 값을 바이트 배열로 변환할 때 사용됐는지 알려줘야한다. 이 속성이 Producer에게 어떤 클래스가 메시지 키를 직렬화 하면서 사용됐는지 나타난다(내장 직렬화 클래스 : ByteArraySerializer, StringSerializer, IntegerSerializer)
- value.serializer : Producer가 값을 직렬화 하기 위해 사용할 클래스를 알려준다. 직접 제작한 직렬화 클래스를 사용할 수도 있다.
- acks : 메시지가 성공적으로 commit 되기 전에 producer가 reader로부터 ACK를 받는 경우사용된다.
- ack=0 : 프로듀서는 서버로부터의 ACK를 기다리지 않는다. 프로듀서는 어느 시점에 메시지가 손실됐는지 모르고, 메시지는 reader broker에 의해서 commit되지 않는다. 이 경우 재시도는 발생하지 않으며, 메시지는 완전히 손실될 수 있다. 이 설정은 매우 높은 처리 성능이 필요하고, 잠재적인 메시지 손실 가능성이 문제되지 않을 경우 사용
- ack=1 : Producer는 reader가 지역 로그에 메시지를 기록하자마자 ACK를 수신한다. Reader가 로그에 메시지 기록을 실패하면 Producer는 retry-policy set에 맞게 데이터를 재전송을 하고, 잠재적 메시지 손실 가능성을 없앤다. 만약 reader가 Producer에 ACK를 반환한 다음, 다른 Broker에게 메시지를 복제하기 전에 다운되면 손실이 발생할 수 있다.
- ack=all : Reader가 모든 복제에 대해 ACK를 수신한 경우에만 Producer는 ACK를 받는다. 장애에 대처할 수 있을 정도로 복제수가 충분하다면 데이터는 손실하지 않는 안전한 설정으로 처리성능이 낮다는 점이 있다.(kafka문서에서는 all을 추천)
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("block.on.buffer.full", "true");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");ProducerRecord 객체
- Producer는 ProducerRecord라는 객체를 제공하는데 Topic 이름, 파티션 번호, timestamp, key, value 등을 포함한다. key 등은 선택 파라미터지만 데이터를 보낼 topic과 value는 반드시 포함해야한다.
- 파티션 번호가 지정되면, 지정된 파티션은 레코드를 전송할 때 사용
- 파티션이 지정되지 않고 키가 지정된 경우 파티션은 키의 해시를 사용
- 키, 파티션 모두 지정하지 않은 경우 파티션은 라운드로빈 방식으로 할당.
ProducerRecord<String, String> recording = new ProducerRecord<String, String>("hello-kafka", "uMsg", msg); producer.send(recording);
Producer 코드
package com.study.kafka;
import java.util.Properties;
import java.util.Scanner;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class Producer {
public static void main(String[] args) throws Exception {
kafkaProducer();
}
private static void kafkaProducer() throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("block.on.buffer.full", "true");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
Scanner scan = new Scanner(System.in);
while (true) {
System.out.print("In > ");
String msg = scan.nextLine();
if (msg.equals("END"))
break;
ProducerRecord<String, String> recording = new ProducerRecord<String, String>("hello-kafka", "uMsg", msg);
try {
producer.send(recording);
} catch (Exception e) {
} finally {
producer.flush();
}
}
producer.close();
}
}Consumer
1. Kafka Consumer의 역할
- Topic 구독하기 : Consumer는 Topic을 구독하면서 시작된다. Consumer Group은 해당 Topic의 파티션 하부 세트가 할당된다. Consumer Process는 할당된 파티션에서 데이터를 읽는다.
- Consumer offset 위치 : Kafka는 메시지 offset을 유지하지 않는다. 그러므로 모든 Consumer는 자신의 consumer offset을 유지해야하고 Consumer API를 사용해 유지한다.
- 재연/되감기/메시지 Skip : Kafka Consumer는 Topic Partition에서 메시지를 읽는 시작점의 offset에 대해 전체적인 제어권을 갖고, Consumer API를 통해 시작 offset을 전달할 수 있다.
- Heartbeat : 지정된 파티션의 멤버쉽과 소유권을 확인하기 위해 Kafka Broker로 Heartbeat 신호를 주기적으로 내보내고, 정해진 시간 간격으로 Broker Reader가 Heartbeat를 수신하지 못하면, 파티션 소유권은 Consumer Group안의 다른 Consumer에게 다시 할당된다.
- offset commit : kafka는 consumer에서 읽는 메시지 위치나 offset을 관리하지 않는다. Consummer는 offset과 commit을 관리한다.
- Deserialization(역직렬화) : Producer는 Kafka에게 메시지를 보내기 전에 바이트 배열로 객체를 직렬화 한다. 마찬가지로 Kafka Consumer는 자바 객체를 바이트 배열로 역직렬화 한다.
2. Consumer 초기설정 파라미터
- bootstrap.server : kafka broker의 host:port 를 입력
- key.desrializer : 메시지 키를 직렬화 할수 있는 클래스를 지정하는 것으로 바이트 배열을 특정 키 형태로 역직렬화 한다.
- value.desrializer : ㅁ메시지를 역직렬화 하기 위해 사용
- group.id : 애플리케이션 생성시 Consumer Group을 정의하는 것은 필요에 따라 Consumer를 관리하고 성능을 향상시키는데 도움을 준다.(필수는은 아니지만 사용을 권장)
- enable.auto.commit : 설정된 주기에 따라 최근에 읽은 메시지의 오프셋을 자동으로 커밋(default : true)
- auto.commit.interval.ms : 매초마다 offster을 커밋하는 설정
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.setProperty("group.id", "test"); props.setProperty("enable.auto.commit", "true"); props.setProperty("auto.commit.interval.ms", "1000"); props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer 객체
KafkaConsumer 객체에 설정값을 넣으면 연결할 broker IP, Consumer Group명, 직렬화 클래스, commit을 하면서 사용할 offset 운영방안 등정보를 알려준다.
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);구독과 폴링
Consumer는 데이터를 받기위해 Topic을 구독한다. KafkaConsumer 객체는 subscribe() 함수를 가지고 있는데, Consumer가 구독하기를 원하는 Topic의 목록을 가져온다.
- public void subscribe(Collection topics) : Consumer가 등록을 원하는 Topic name 목록을 전달하는 것으로 메시지 데이터 처리에 영향을 줄 수 있는 default rebalancer(기본 리벨런서)를 사용
- public void subscribe(Pattern pattern, ConsumerRebalanceListener listener) : kafka에 존재하는 적합한 Topic을 대응시키는 Regex(정규식)을 전달하고 동적으로 처리한다. 정규식에 대응하는 새로운 토픽의 추가나 삭제시 리밸런서를 트리거한다. CoonsumerRebalanceListener는 해당 인터페이스를 구현하는 자신의 클래스를 가져오는 역할을 한다.
- public void subscribe(Collection topics, ConsumerRebalanceListener listener) : 토픽의 목록을 전달하고, ConsumerRebalanceListener를 수반한다.
consumer.subscribe(Arrays.asList("hello-kafka"));폴링은 kafka topic에서 데이터를 가져오는 것으로 consumer가 아직 읽지 않은 메시지를 반환한다.
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}Consumer 코드
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class Consumer {
public static void main(String[] args) throws Exception {
kafkaConsumer();
}
private static void kafkaConsumer() throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("hello-kafka"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}결과
'Back-End > Kafka' 카테고리의 다른 글
| [Kafka] 5. kafka topic message 처리하기 (0) | 2023.04.25 |
|---|---|
| [Kakfka] 4. Kafka clusters (0) | 2023.04.24 |
| [Kakfa] 2, Kafka QuickStart (0) | 2023.04.24 |
| [Kafka] 1. Apache Kafka 개념 및 소개 (0) | 2023.04.24 |
| [Kafka] 0. Apache Zookeeper (0) | 2023.04.24 |