Apache Spark
Apache Spark는 분산된 메모리상의 데이터 처리 시스템이며, 2009년 버클리 대학교의 AMPLab에서 MapReduce Framework 성능을 향상시키기 위해 시작되었다. Spark는 기본적으로 맵리듀스 개념을 사용하지만, Spark만의 데이터 처리 방법 및 task 처리 방법으로 인해 메모리 내의 연산 속도가 Hadoop보다 100배 가량 빠르고 디스크에 저장되어 있을 때는 10배 빠르다. Spark는 Batch와 실시간 데이터 처리 분석, 머신러닝, 단일 클러스터 플랫폼상의 거대한 데이터 그래프 처리 등을 위한 Application 개발에 사용되며, 자바, 스칼라, 파이썬에 대한 풍부한 APIs를 제공한다.
장점
- 맵리듀스(MapReduce)와 유사한 일괄 처리 기능
- 실시간 데이터 처리 가능(Spark Streamin)
- SQL과 유사한 정형 데이터 처리 기능 제공(Spark SQL)
- 그래프 알고리즘 제공(Spark GraphX)
- 머신러닝 알고리즘 제공(Spark MLlib)
- 많은 데이터를 메모리에 캐시할 수 있어서 데이터 변환처럼 반복 접근 방식을 쓰는 Application의 성능이 향상되도록 캐시의 장점을 활용 가능하다.
스파크의 구조
- Spark는 Hadoop과 같이 Master/Slave 구조이며, Master인 상주 프로그램(Daemons)은 스파크 드라이버라고(Spark Driver)하고, Multi Salve인 상주 프로그램(Daemons)은 실행기(executors)라고 한다.
[Spark 구조]
- Spark는 Cluster에서 실행되고, YARN, Mesos, Spark 독립 클러스터 관리자 등과 같은 Cluster 자원 관리자를 사용한다.

Spark Driver
Spark Driver는 구조상 Master이며, Spark Application의 시작점이다.
- SparkContext(스파크 컨택스트) : Context는 Spark Driver에서 생성되고 Context 객체는 Application 설정을 초기화 하는 역할도한다.
- DAG 생성 : Spark Driver는 RDD(Resilient Distributed Dataset, 복원 분산 데이터 셋) 운영을 기반으로 계보를 생성하여 DAG(Directed Acyclic Graph, 방향성 비순환 그래프) 스케줄러에 등록하는 역할을 한다. 계보란, 방향성 비순환 그래프로, 이 그래프는 DAG스케줄러에 등록된다.
- Stage 생성 : Driver안의 DAG 스케줄러는 계보 그래프에 기초한 task(작업)의 스테이지를 생성하는 역할을 한다.
- 작업 스케쥴러 실행 : 작업 스테이지가 생성되면 드라이버 안에서 작업 스케줄러는 클러스터 관리자를 사용해 단위 작업 일정을 설정하고, 실행을 제어한다.
- RDD 메타데이터 : 드라이버는 RDD의 메타데이터와 해당 파티션을 유지한다. 파티션에 장애가 발생할 경우 스파크는 파티션이나 RDD를 쉽게 다시 산출한다.
Spark Worker
Spark Workersms 실행 중인 Launcher(실행기)를 관리하고 Master Node와 통신을 수행하는 역할을 한다.
- Backend Process : 단위 작업자 노드는 하나 이상의 백엔드 프로세스를 가지고, 각각의 백엔드 프로세스는 실행기를 시작시키는 역할을 한다.
- Launcher(실행기) : 단위 실행기는 작업을 병렬로 수행하는 역할을 Thread Pool로 구성되며, 실행기는 데이터의 지정된 위치나 파일에서 읽고, 쓰고 처리한다.
Spark의 핵심 - RDD(Resilient Distributed Dataset)
RDD는 Spark의 중심축으로, 변하지 않고, 내결함성을 갖는 분산된 객체의 집합이다. RDD는 논리적인 파티션으로 구분되고, 여러 작업자 컴퓨터에 의해 산출된다.
[과정]
Spark에서 어떤 파일을 읽을경우, 해당 데이터는 하나의 큰 RDD를 형성한다. RDD상에서 필터리 작업은 새로운 RDD를 성형하고, RDD는 불변성을 가지는데, 이는 RDD를 수정할 때마다 새로운 RDD를 가지게 된다는 의미다. 이런 RDD는 파티션이라는 논리적 구역으로 구분하고, Spark에서 병렬처리 단위가 된다. 단위 구역 또는 파티션은 별 개의 분산 컴퓨터에서 처리된다.
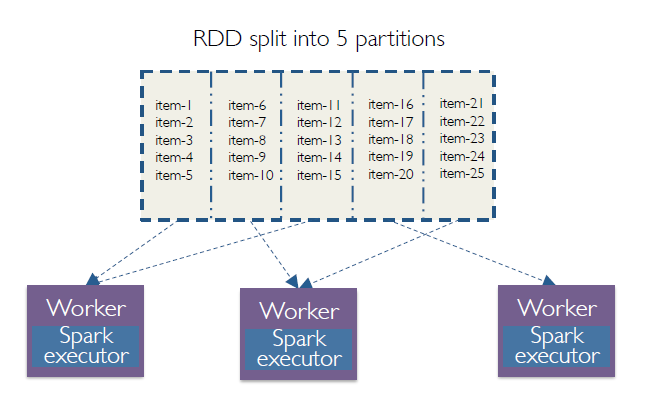
RDD 상에서 수행되는 두 가지 작업 유형
변환 : RDD 상에서 변환은 또 다른 RDD를 생성하고, 필터를 적용하거나, 기존의 RDD를 수정하는 것이며, 이는 새로운 RDD를 생성하게 된다.
액션(Action) : 스파크에 대해 실행 트리거 역할을 한다. 스파크는 RDD에대해 수동적인데, 이는 스파크가 액션을 만나지 못하면 실행 자체를 시작하지 않는다. (액션의 의미 : 파일로 결과를 저장하거나, 콘솔에 결과를 출력하는 등의 작업을 의미)
DAG : RDD는 변환이 가능하며 그 결과는 새로운 RDD를 생성하는 것이고, 이 과정은 어떤 액션을 실행하기까지 계속 진행된다. 어떤 Action을 만날 때마다 Spark는 DAG를 생성하고 나서 스케줄러에 등록한다. 일단 DAG가 등록되면 DAG 스케줄러는 연산자를 사용하여 작업 단계를 생성한다. 작업 스케줄러는 클러스터 관리자와 작업자 노드의 도움을 받아 작업을 수행한다.
Spark 운영환경
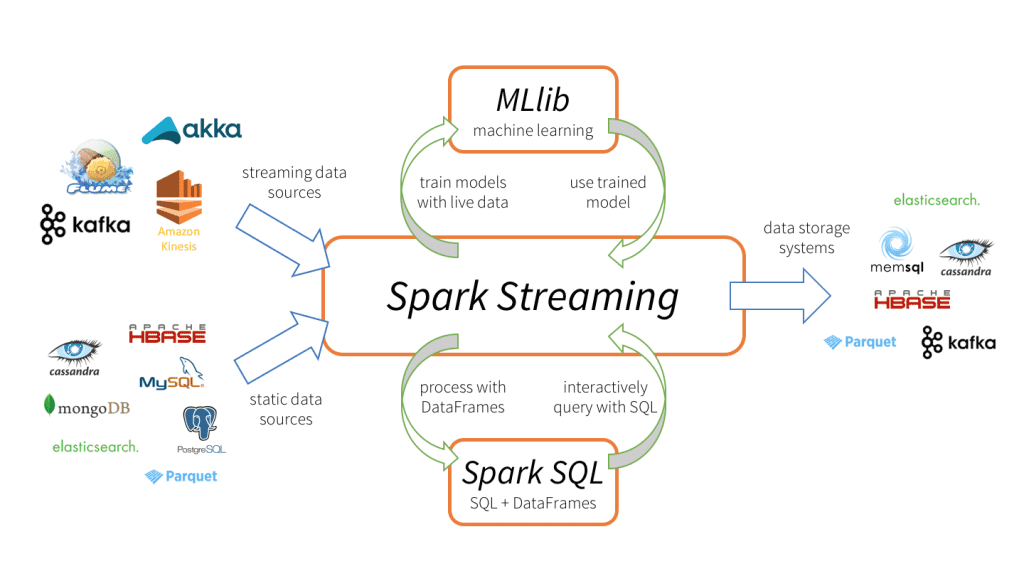
Spark Core : Spark Core는 Spark 운여환경에서 기초가되는 범용적인 계층이다. 모든 계층에서 활용가능하고 공동적인 기능이 포함한다. 스파크 주요 추상화 부분인 RDD Core도 Core 계층의 일부분이고, RDD를 다루기 위한 API도 Core에 포함된다. 또한 스케줄러, 메모리 관리자, 내결함성, 저장소 작용 계층(storeage interaction layer)등 공통 구성 요소도 Spark 코어의 일부이다.
Spark Streaming : 실시간 스트리밍 데이터 처리에 사용된다. Spark Streaming은 엄밀하게 실시간은 아니지만, 마이크로 배치 단위로 데이터를 처리함으로 실시간에 가깝다.
Spark SQL : Spark SQL은 SQL 질의어를 JSON RDD와 CSV RDD 같은 구조화된 RDD상에서 활용하도록 API를 제공.
Spark MLlib : 확장성 있는 머신러닝 솔루션을 생성하는데 사용. 회귀(Regression), 분류작업(Classification), 클러스터나 필터링 같은 풍부한 머신러닝 알고리즘 세트를 제공
Spark GraphX : 복잡한 사회관계망을 기반으로 추천 엔진을 제작하는 등의 그래프 처리가 중요한 역할을 하는 상황을 다루는데 활용.
참조
https://medium.com/@thejasbabu/spark-under-the-hood-partition-d386aaaa26b7
