Apache Spark Apache Spark는 분산된 메모리상의 데이터 처리 시스템이며, 2009년 버클리 대학교의 AMPLab에서 MapReduce Framework 성능을 향상시키기 위해 시작되었다. Spark는 기본적으로 맵리듀스 개념을 사용하지만, Spark만의 데이터 처리 방법 및 task 처리 방법으로 인해 메모리 내의 연산 속도가 Hadoop보다 100배 가량 빠르고 디스크에 저장되어 있을 때는 10배 빠르다. Spark는 Batch와 실시간 데이터 처리 분석, 머신러닝, 단일 클러스터 플랫폼상의 거대한 데이터 그래프 처리 등을 위한 Application 개발에 사용되며, 자바, 스칼라, 파이썬에 대한 풍부한 APIs를 제공한다. 장점 맵리듀스(MapReduce)와 유사한 일괄 처리 기능 ..
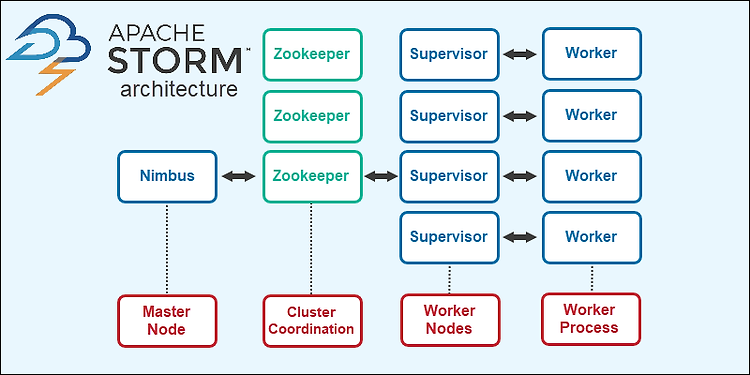
Apache Storm Apache Storm은 분산형 실시간 처리 프레임워크로써, 노드마다 초당 수백만 개의 레코드를 처리하고 한 번에 하나씩 이벤트를 처리하는 기능이 있다. 그리고 1초의 지연마저도 큰 손실이 되는 매우 민감한 어플리케이션을 다루는데 사용되고, 추천엔진 제작, 의심스런 활동 트리거 등에 사용하고 있다. 또한 상태 저장 없이(stateless), 중요한 메타데이터 정보를 유지하기 위한 조정(coordinating)을 목적으로 주키퍼를 사용한다. 클러스터 구조 스톰은 마스터-슬레이브(master-slave)구조로 되어있고 님버스(nimbus)가 마스터이고, 수퍼파이저(supoervisor)가 슬레이브가 된다. 님버스(nimbus) : 스톰 클러스터 마스터노드로 클러스터 안에서 나머지 모든..