Greedy Algorithm(탐욕 알고리즘) 정의 탐욕 알고리즘은 최적해를 구하는 데에 사용되는 근사적인 방법으로, 여러 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식으로 진행하여 최종적인 해답에 도달한다. 순간마다 하는 선택은 그 순간에 대해 지역적으로는 최적이지만, 그 선택들을 계속 수집하여 최종적(전역적)인 해답을 만들었다고 해서, 그것이 최적이라는 보장은 없다. 동적 계획법과 탐욕 알고리즘의 차이 동적 계획법은 최적의 해를 구하긴 하지만 탐욕 알고리즘 보다는 덜 효율적이다. 반면 탐욕 알고리즘은 동적 계획법보다 효율적이긴 하지만 반드시 최적의 해를 구해준다는 보장은 하지 못한다.(최적 해가 나오기를 바랄 뿐) 동작과정 동적 계획법처럼 대상 문제가 최적..
분류 전체보기
Devied And Conquer(분할정복) 정의 기본적으로는 엄청나게 크고 방대한 문제를 조금씩 조금씩 나눠가면서 직접 풀 수 있는 문제가 간단해질 때까지 재귀적으로 분할하고 부속문제들의 해답들이 다시 합쳐서 해결하자는 개념 문제를 더 이상 나눌 수 없을 때까지 나눈 후 문제들을 해결하며 병합하여 결과 값을 얻는 알고리즘 알고리즘 설계 방법 (1) Devied(분할) : 문제가 분할이 가능한 경우, 2개 이상 하위 문제로 나눈다. (2) Recursion(재귀) : 재귀적으로 부속문제들을 푼다. (3) Conquer(정복) : 해답들을 적절하게 합친다. 중요사항 문제를 잘 나누는 것 문제를 잘 합치는 것 분할 정복 기법에서는 재귀를 이용하여 비슷한 종류의 부속 문제들을 해결 장점 어려운 문제를 해결한다..
Sort(정렬) 데이터를 정렬 하는 것! 정렬 알고리즘의 방법 내부 정렬 알고리즘(Internal Sort Algorithm) : 메모리에 있는 데이터를 정렬 외부 정렬 알고리즘(External Sort Algorithm) : 파일이나 외부의 특정 저장공간에 있는 데이터를 정렬 직접 정렬 알고리즘(Direct Sort Algorithm) : 실제 데이터를 직접 재배치하며 정렬 간접 정렬 알고리즘(Indirect Sort Algorithm) :데이터가 저장된 주소 값만을 바꾸어 정렬 정렬 알고리즘의 선택 어떤 데이터를 사용하는가? 어떤 정렬 조건을 사용하는가? 종류 Insert Sort Selection Sort Bubble Sort Merge Sort Quick Sort 등이 있다. 1. Selectio..
Dynamic Programming(동적 계획법) 동적 계획법(Dynamic Programming)은 풀고자하는 복잡한문제가 여러단계의 반복되는 부분문제로 이루어졌을 때 각 단계 있는 부분 문제의 답을 기반으로 전체 문제의 답을 구하는 알고리즘 기법이다. 문제를 부분 문제로 단계적으로 나누고, 가장 작은 부분 문제의 답부터 구해 올라오면서 전체 문제의 해를 구하는 것. 계획법(Programming)이란 용어는 코딩(cooding)이 아니라 테이블을 채운다는 문자적 의미(선형 계획법과 유사) 동적 계획법의 특징 작은 하위 문제들의 해결을 통해 전체 문제의 최적해를 구한다. 큰 문제를 작은 문제로 나눌 수 있어야 한다. 모든 하위 문제들의 해결 과정에서 중복되는 계산을 피하기 위해 메모이제이션(memoiza..
Priority Queue(우선순위 큐) 입력된 순서대로 출력되는 것이 아닌 데이터의 우선순위에 따라 출력순서가 결정되는 것. 핵심 = 데이터의 입/출력이 이루어질 때 최소의 비용으로 최소 우선순위의 데이터를 헤드에 위치시키는 것. 우선순위 큐는 삽입과 제거의 연산을 지원하는 자료구조 우선순위 큐의 구현방법 배열기반으로 구현하는 방법 연결리스트로 구현하는 방법 힙으로 구현하는 방법 기본원리 (아래 조건은 배열 or 연결리스트로 구현하는 것을 예 로듬) 데이터가 작으면 우선순위가 높은 걸로 가정 우선순위 큐의 삽입 연산 20이란 데이터를 집어 넣으려고 하면 queue에 있는 리스트들을 검색하여 19 보단 크고 21보다는 작은 데이터 사이에 추가한다. 우선순위 큐의 제거 연산 제일 앞에 있는 데이터를 제거한..
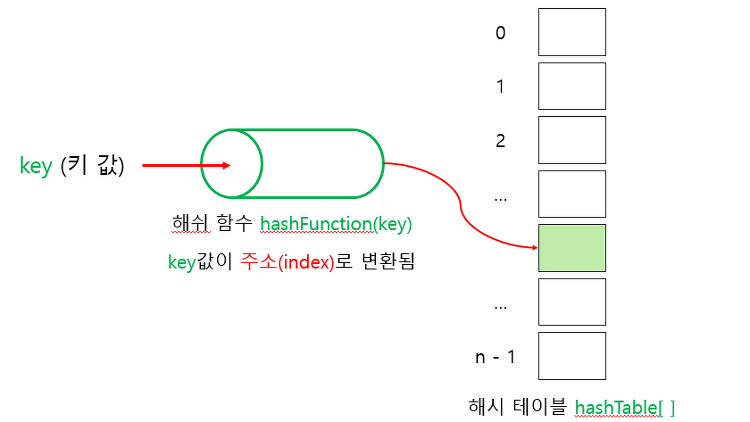
Hash(해시) 정의 인덱스를 사용하는 알고리즘으로 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수이다 데이터를 입력받고 완전히 다른 모습의 데이터로 바꾸어 놓는 작업 잘게 부수고 다시 뭉치는 것 대용량의 데이터를 검색할 때 주로 사용 효율적인 탐색 알고리즘을 위한 자료구조로써 Key를 Value에 대응시킨다. 사전구조 개념 사전구조는 map이나 table로 불리고 key와 value 두 가지 종류의 필드를 가진다. 데이터에 접근하고 삭제할 때 탐색할 key값만 알 수 있으면 된다. 해시의 사용용도 해시테이블(Hash Table) : 데이터의 해시 값을 테이블 내의 주소로 이용하는 궁극의 탐색 알고리즘이다. 암호화 : 해시는 입력받은 데이터를 완전히 새로운 모습의 데이터로 만든다.(ex- S..
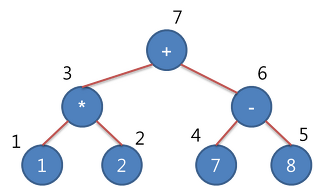
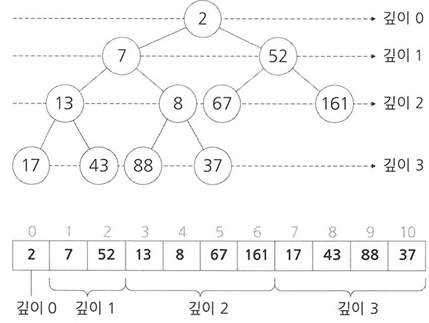
Tree(트리) 나무와 유사하게 비선형(데이터가 계층적 구조로 이루어짐) 구조로 이루어져 있는 자료구조 트리는 다른 자료구조보다 자료를 저장하거나 검색하는 방법이 간단하고 메모리를 효율적으로 사용할 수 있다. 구성 트리는 크게 Root(뿌리), Branch(가지),leaf(잎) 세 가지 요소로 이루어짐 Root : 트리 구조에서 최상위에 존재하는 노드이다. Branch : Root Node or Sub Tree 와 leaf 사이에 있는 노드를 말한다(자식). Leaf(Terminal Node) : Branch Node의 맨 끝에 달려있는 노드로, 밑으로 또 다른 노드가 연결되어 있지 않은 노드를 말한다(Terminal(단말)노드). Node : 트리의 구성요소에 해당하는 요소를 말한다. Edge : 노드..
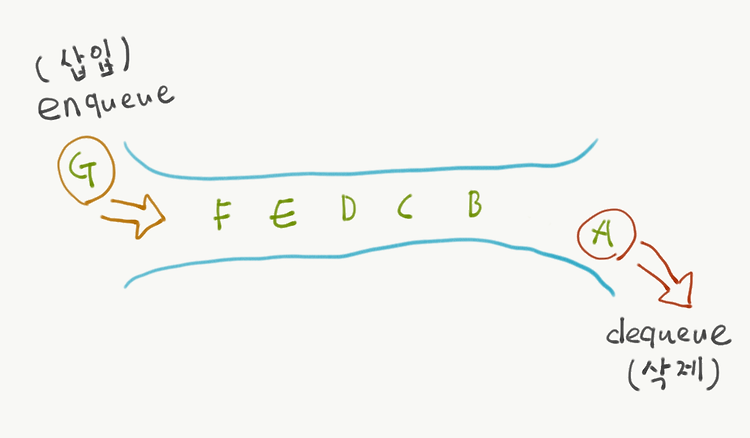
Queue(큐) 정의 한쪽 끝에서 자료를 넣으면 다른 한쪽 끝에서 자료를 뺄 수 있는구조로 쉽게 말해서 먼저들어온 데이터가 먼저 나오는 구조라고해서 FIFO(First In First Out)라고 부른다. 큐의 연산 enqueue : 데이터를 큐에 삽입 dequeue : 제일 첫 번째 들어온 데이터를 제거 큐의 전단은 front, 후단은 rear로 이루어짐 새로운 데이터가 들어오면 rear가 하나씩 증가 데이터를 빼내면 front가 다음 queue에 저장되어 있는 데이터를 가리킴 enqueue void enqueue(Object[] queue, int data) { queue[rear++] = data; } dequeue Object dequeue(Object[] queue) { queue[front++..
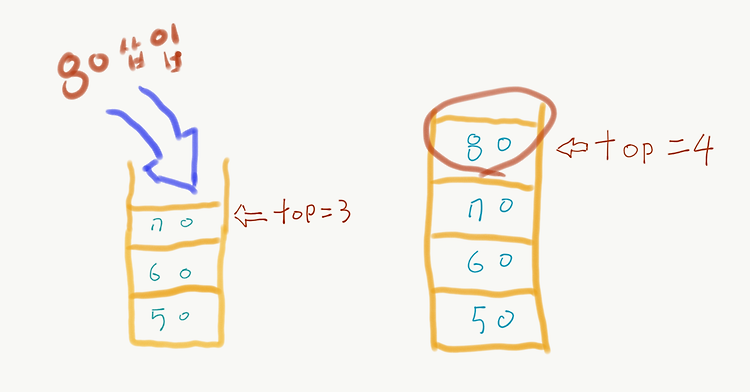
스택(Stack) 먼저 들어간 데이터가 가장 마지막에 나오는 구조(Last In, First Out : LIFO) 삽입과 삭제가 한쪽 끝에서만 자료를 넣고 뺄 수 있다. ex) 자동메모리, 네트워크 프로토콜 스택(Stack)의 주요 기능 스택의 초기화 int stack[100]; //스택 배열 int size = 0; // 스태의 크기 삽입(Push) 스택 위에 새로운 노드를 쌓는 작업 void push(int data) { stack[size] = data; size = size + 1; } 삭제(Pop) 스택에서 최상위 노드를 걷어내는 작업 int pop() { if (size < 0) return 0; int pop = stack[size]; size = size - 1; return pop; } ..
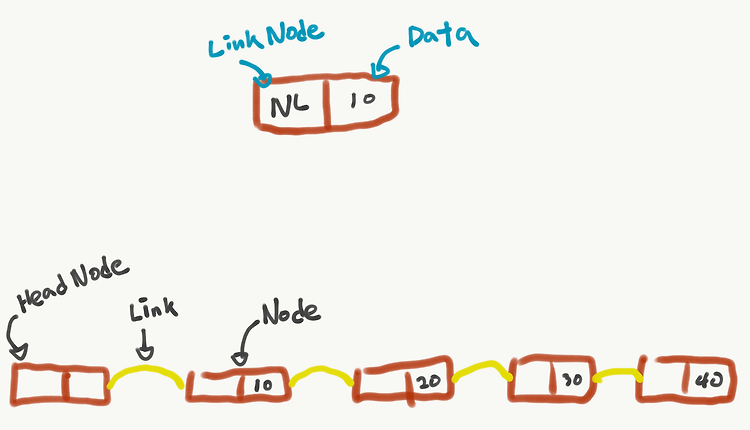
Linked List(연결리스트) 개념과 구조 데이터가 연속적인 리스트 새로운 노드를 삽입하거나 삭제가 간편 링크라는 개념을 통해 물리 메모리를 연속적으로 사용하지 않아도 된다. 데이터를 구조체로 묶어 포인터로 연결 Linked List에는 기본적으로 Node와 Link라는 용어를 사용 HeadNode에는 데이터를 저장하지 않는다. 단지 LinkedList의 시작부분임을 나타낸다.(ex:기관차에서 headNode는 승객이 타지 않음) LinkedList의 마지막 부분을 나타내는 노드도 있다. End Node or Tail Node라고 불리며, 데이터를 저장하지 않는다. 즉, Head, Tail(End) 노드는 데이터를 저장하지 않음(저장할 수 없다는 것이 아니라 묵시적으로 데이터를 저장하지 않는다는 것)..